最近在做 OpenGraph 相关的工作,需要根据网址返回页面的首屏截图,毫无疑问无头浏览器已发展多年,已足够可靠,直接使用 Nodejs 集成 Puppeteer 就好。
无头浏览器是什么?
无头浏览器(Headless Browser)是一种没有图形用户界面(GUI)的网络浏览器。它能够执行与常规浏览器相同的功能,但没有可见的窗口或界面。无头浏览器可以在后台运行,加载和渲染网页,执行JavaScript代码,并提供对网页内容的访问和操作。它可以模拟用户与网页的交互,如点击链接、填写表单、提交数据等。通过无头浏览器,开发人员可以编写自动化脚本来测试网站的功能、执行网络爬虫任务或进行其他与浏览器相关的自动化操作。
- Puppeteer: 一个 Node.js 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chrome/Chromium
- Playwright: 支持对现代 Web 应用程序进行可靠的端到端测试。
- Crawlee: Web 抓取和浏览器自动化库
但是,这在 Nextjs 的 Vercel 部署遇到了问题,它失败了!
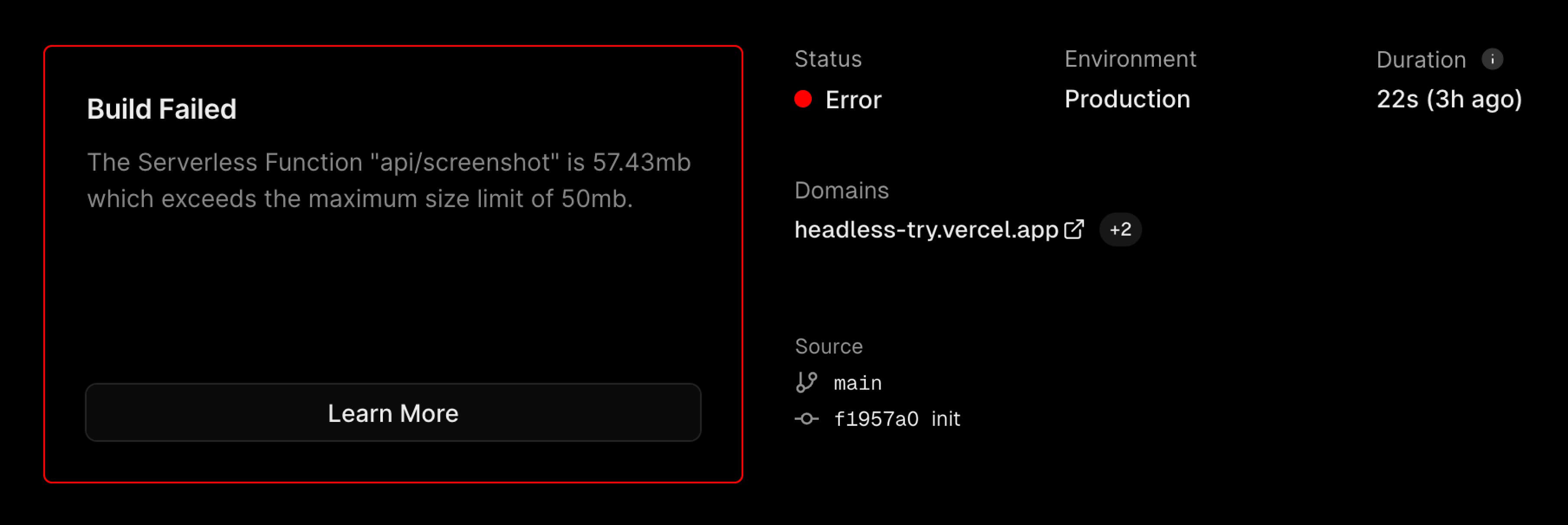
好吧,出问题了! 于是我找到了这个 Exceeding size limits (50mb) for Serverless Functions
看来这个问题已经蛮多人遇到了,看到提到的解决方案有这个
Traced Next.js server files in: 423.26ms
--
23:27:46.148 | Warning: Max serverless function size of 50 MB compressed or 250 MB uncompressed reached
23:27:46.148 | Serverless Function's page: api/get-mls-entries.js
23:27:46.151 | Large Dependencies Uncompressed size Compressed size
23:27:46.151 | node_modules/chrome-aws-lambda/bin 49.6 MB 49.5 MB
23:27:46.151 | node_modules/next/dist 3.09 MB 957 kB
23:27:46.151 | node_modules/puppeteer-core/lib 536 kB 137 kB
23:27:46.151 | node_modules/lodash/lodash.js 544 kB 96.4 kB
23:27:46.151 | node_modules/parse5/dist 589 kB 89.5 kB
chrome-aws-lambda: AWS Lambda 和 Google Cloud 函数的二进 Chromium
大小在 50M 内,很接近了,还有个问题是 aws-lambda 已经多年不维护了,内核版本有些旧了,我们来想想其他办法。
远程内核
@sparticuz/chromium:AWS Lambda 的后继维护版
在文档种找到了这个
If your vendor does not allow large deploys (
chromium.bris 50+ MB), you'll need to host thechromium-v#-pack.tarseparately and use the@sparticuz/chromium-minpackage.如果您的供应商不允许大型部署(chromium.br 为 50+MB),您将需要单独托管 Chrome-v#-Pack.tar 并使用
npm install --save @sparticuz/chromium-min@$CHROMIUM_VERSION
使用单独托管的包
const browser = await puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath(
"https://www.example.com/chromiumPack.tar"
),
headless: chromium.headless,
});
思路
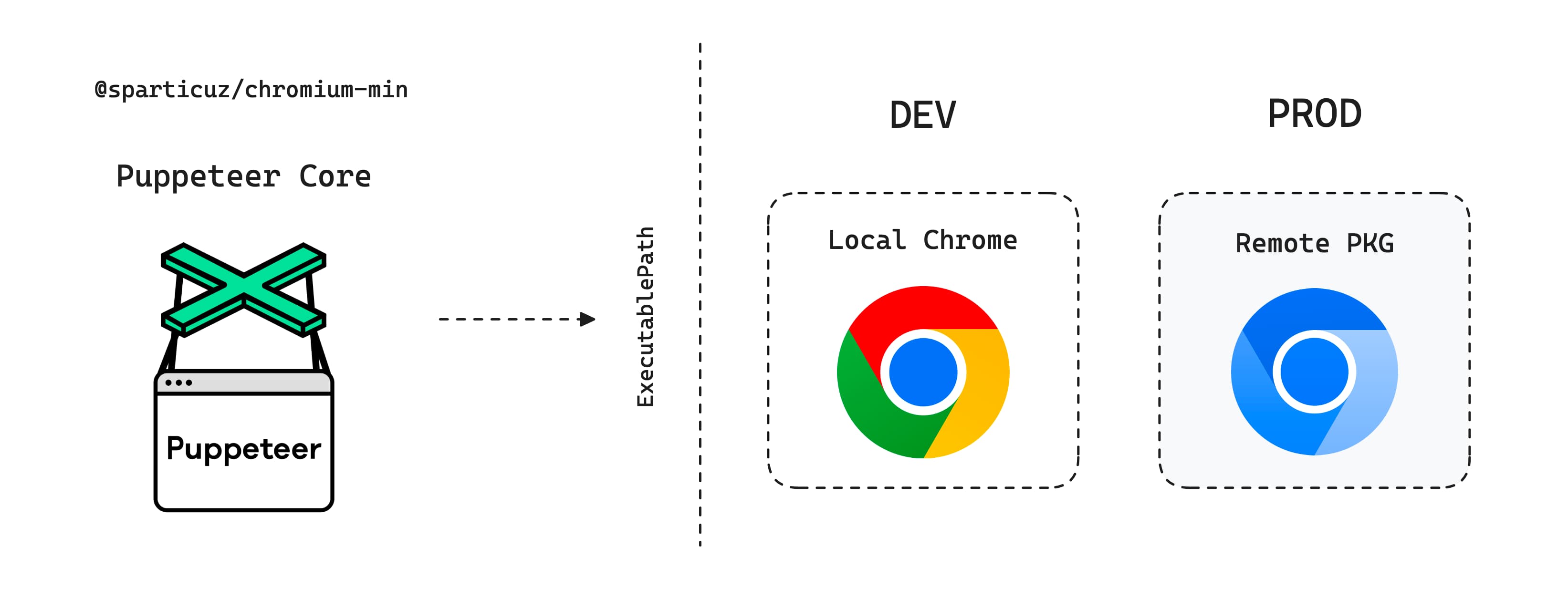
开发模式 开发直接使用本地包(你电脑上的 Chrome 浏览器),不同系统的本地包路径不同。
生产模式 使用远程 Chromium 二进制包,它是一互联网文件地址,建议使用 github 的公开包地址,否则私有地址要注意流量问题。
搭建
创建 Nextjs 项目,创建完毕后安装需要的依赖
开发依赖
npm install @sparticuz/chromium-min@119 puppeteer-core@21
安装完毕后
{
"dependencies": {
"@sparticuz/chromium-min": "^119.0.2",
"puppeteer-core": "^21.6.1"
}
}
创建接口路由 /src/app/try/route.js
// 本地 Chrome 执行包路径
const localExecutablePath =
process.platform === "win32"
? "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
: process.platform === "linux"
? "/usr/bin/google-chrome"
: "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
// 远程执行包
const remoteExecutablePath =
"https://github.com/Sparticuz/chromium/releases/download/v119.0.2/chromium-v119.0.2-pack.tar";
// 运行环境
const isDev = process.env.NODE_ENV === "development";
在“开发模式”下使用本地 Chrome 的执行路径,否则使用远程包执行路径。
更多远程执行包,可以查看 Sparticuz/chromium
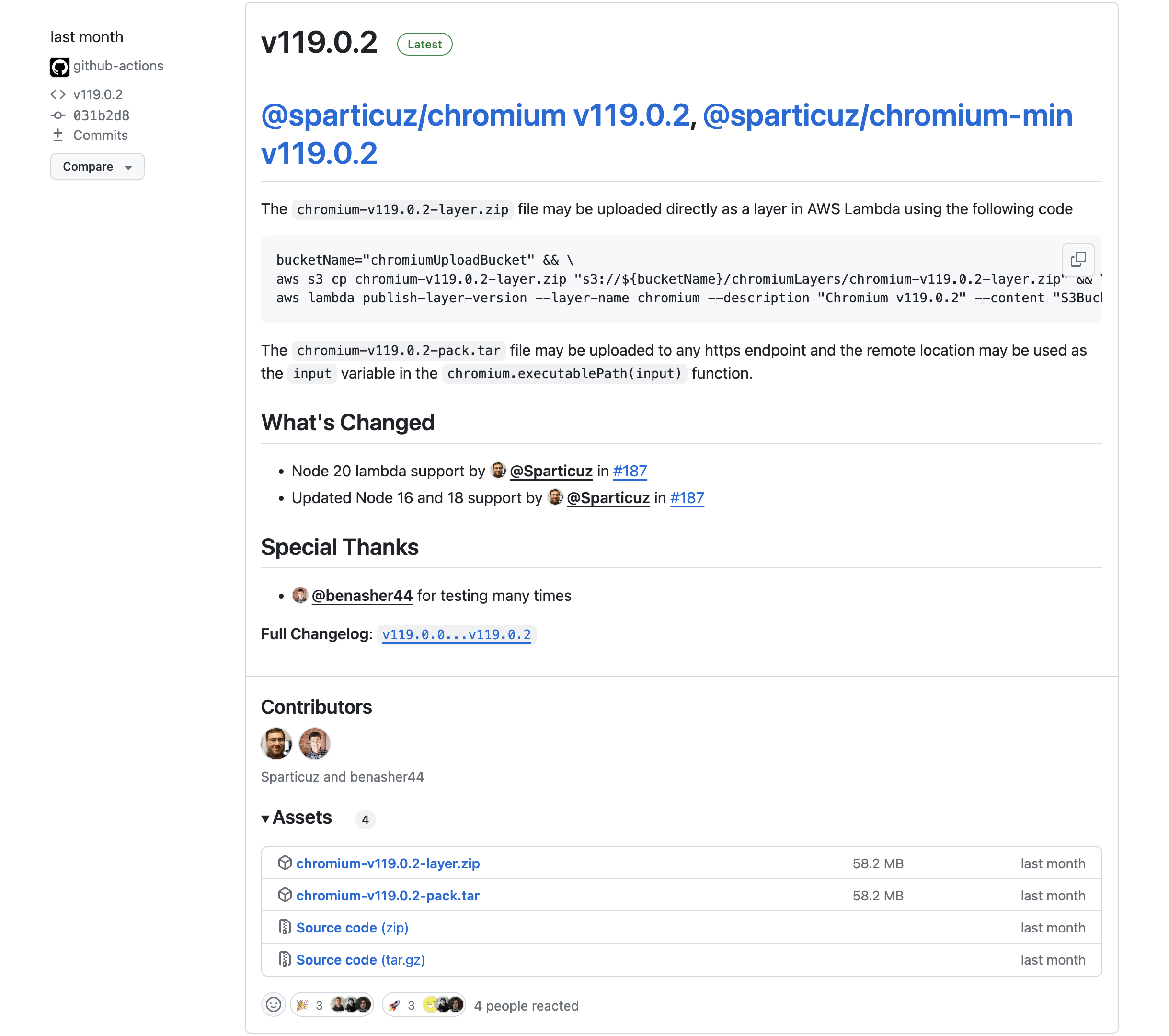

export const maxDuration = 60; // This function can run for a maximum of 60 seconds (update at 2024-05-09 form 10 seconds)
export const dynamic = "force-dynamic";
export async function GET() {
let browser = null;
try {
// 引入依赖
const chromium = require("@sparticuz/chromium-min");
const puppeteer = require("puppeteer-core");
// 启动
browser = await puppeteer.launch({
args: isDev ? [] : chromium.args,
defaultViewport: { width: 1920, height: 1080 },
executablePath: isDev
? localExecutablePath
: await chromium.executablePath(remoteExecutablePath),
headless: chromium.headless,
});
// 打开页面
const page = await browser.newPage();
// 等待页面资源加载完毕
await page.goto("https://hehehai.cn", {
waitUntil: "networkidle0",
timeout: 100000,
});
// 打印页面标题
console.log("page title", await page.title());
const blob = await page.screenshot({ type: "png" });
const headers = new Headers();
headers.set("Content-Type", "image/png");
headers.set("Content-Length", blob.length.toString());
// 响应页面截图
return new NextResponse(blob, { status: 200, statusText: "OK", headers });
} catch (err) {
console.log(err);
return NextResponse.json(
{ error: "Internal Server Error" },
{ status: 500 }
);
} finally {
// 释放资源
await browser.close();
}
}
args: isDev ? [] : chromium.args: “开发模式”不需要设置执行包的命令行参数executablePath: 用来配置执行包路径- “开发模式”
localExecutablePath - “非开发模式”
await chromium.executablePath(remoteExecutablePath)
- “开发模式”
这里不过多介绍 Puppeteer 的运行配置了就,更细节的优化配置可以参考官方文档
启动程序
npm run dev
> headless-try@0.1.0 dev
> next dev
▲ Next.js 14.0.4
- Local: http://localhost:3000
- Environments: .env.local
✓ Ready in 2s
🤨 出现错误
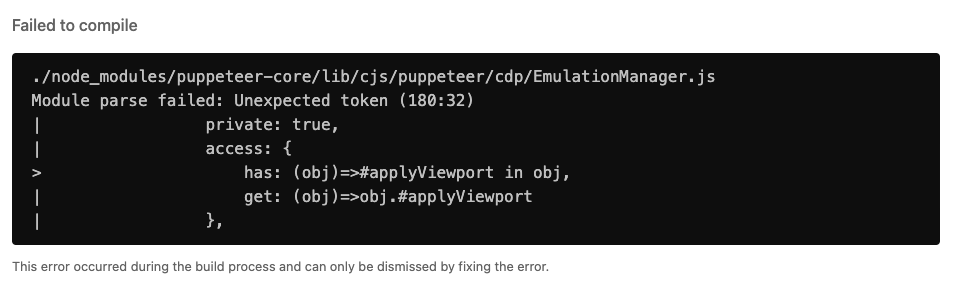
⨯ ./node_modules/puppeteer-core/lib/cjs/puppeteer/cdp/EmulationManager.js
Module parse failed: Unexpected token (180:32)
| private: true,
| access: {
> has: (obj)=>#applyViewport in obj,
| get: (obj)=>obj.#applyViewport
| },
Import trace for requested module:
./node_modules/puppeteer-core/lib/cjs/puppeteer/cdp/EmulationManager.js
./node_modules/puppeteer-core/lib/cjs/puppeteer/cdp/cdp.js
./node_modules/puppeteer-core/lib/cjs/puppeteer/puppeteer-core.js
./src/app/try/route.js
require 包引入
你会发现我们使用的依赖包是使用 require 方式引入的,Nextjs 默认优化了一部分 Nodejs 包,这些使用 require 引入是会自动处理的,好在 Nextjs 提供了配置。
next.config.js
/** @type {import('next').NextConfig} */
const nextConfig = {
experimental: {
serverComponentsExternalPackages: [
"puppeteer-core",
"@sparticuz/chromium-min",
],
},
};
module.exports = nextConfig;
serverComponentsExternalPackages: 如果依赖项使用 Nodejs 特定功能,您可以选择从服务器组件捆绑中选择退出特定依赖项并使用本机 Nodejs require 。
保存后,重新启动服务,访问 http://localhost:3000/try

...
✓ Ready in 1710ms
✓ Compiled /try in 224ms (40 modules)
page title Hehehai @一块木头 - 全栈开发,专注于前端应用程序和用户界面设计.
🥳🥳🥳 速度还是很快的
部署 vercel
Fork headless-try repo
登录 verlcel 登录后,进入 Dashboard,创建项目
选择 headless-try
点击 Deploy 按钮
部署成功后,访问 Domains 点击 Blog screenshot 链接, 部署在 vercel 的免费网页,截图的运行时间是 10s, 所以如果在 10 内,没有返回结果,那么是超时了!可以重试几次,有缓存后就快一点了,测试一般在 5s。

在 Cloudflare 中使用 headless
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add the ?url=https://example.com/ parameter"
);
}
},
};
🥳 好消息:Workers Browser Rendering API enters open beta
🫠 坏消息:还在内测中, 快来申请 Add yourself to the waitlist
Browserless
除此外,还有种独特的方式,Puppeteer 允许通过 browserWSEndpoint 选项指定 chrome 的远程位置,就像这样
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://localhost:3000",
});
我们需要一个 ws 的 chrome 远程服务来被调用。 好在它已经出现了 👏👏👏 Browserless!
Browserless 允许远程客户端连接并执行无头工作,所有这些都在 Docker 内部。它支持标准的、未分叉的 Puppeteer 和 Playwright 库,并为数据收集、PDF 生成等常见操作提供基于 REST 的 API。
它是开源的,可以使用 Docker 部署在服务器上。
// Next.js API route support: https://nextjs.org/docs/api-routes/introduction
import type { NextApiRequest, NextApiResponse } from 'next'
import puppeteer from 'puppeteer-core'
type Json = {
message: string
}
export default async function handler(
req: NextApiRequest,
res: NextApiResponse<Json | Buffer>
) {
const { searchParams } = new URL(
req.url as string,
`http://${req.headers.host}`
)
const url = searchParams.get('url')
if (!url) {
return res
.status(400)
.json({ message: `A ?url query-parameter is required` })
}
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io?token=${process.env.BLESS_TOKEN}`,
})
const page = await browser.newPage()
await page.setViewport({ width: 1920, height: 1080 })
await page.goto(url)
return res.status(200).send(await page.screenshot({type: 'png'}))
}